deb and rpm packages work well, provided dependencies are crafted carefully, to avoid
dependency spaghetti (or dependency hell)
I have run Debian production systems for 7 years or so, and I rarely see aptitude struggle to find a good solution.
Right now I am testing out the latest Debian (Squeeze), and it provides an example, that I have worked through on one system, and want to document here.
During testing, I noticed that my file manager Thunar was not automatically picking up changes to the underlying directory.
File alteration monitors (fam or gamin) generally look after this functionality.
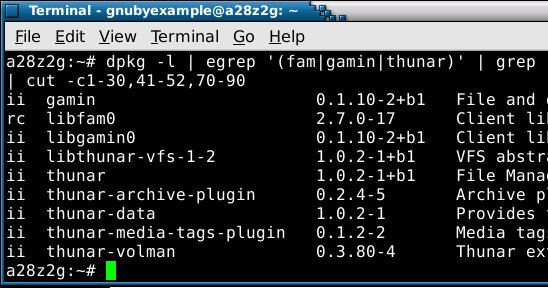
Currently the system is using fam and here is a summary from dpkg:

which says that fam rather than gamin is providing the alteration monitor for my system.
Now the logical thing to do I thought would be to switch to gamin and see if that fixed my issue (described in paragraph 4)
Here aptitude tells me that Thunar recommends gamin:

Here is a screenshot of what aptitude thinks of my attempt to switch away from using fam:

Now removing libfam0 seems like the logical thing to do...
...but a quick look at the dependencies for libfam0, caused me a moment of pause:

And the way to reassure yourself is to preview the changes after choosing (!: Apply):

The output from aptitude includes the phrase 'removing anyway as you requested', which has me wondering?

Now a dpkg summary shows my system having gamin installed rather than fam:

The key to understanding how and why this works is to realise that, in Debian Squeeze, libgamin0 has been marked as a drop in replacement for libfam0 as shown here:

Which means that you can ignore any 'removing anyway as you requested' messages, and know that your system, has not been broken by your actions.
My system has no Nautilus file manager but instead uses Thunar:

...and as thunar recommends gamin, it is a shame that gamin, rather than fam, was not on my system automatically.
Now to see if my file manager is picking up changes to the underlying files in realtime :)
During testing, I noticed that my file manager Thunar was not automatically picking up changes to the underlying directory.
File alteration monitors (fam or gamin) generally look after this functionality.
Currently the system is using fam and here is a summary from dpkg:

which says that fam rather than gamin is providing the alteration monitor for my system.
Now the logical thing to do I thought would be to switch to gamin and see if that fixed my issue (described in paragraph 4)
Here aptitude tells me that Thunar recommends gamin:

Here is a screenshot of what aptitude thinks of my attempt to switch away from using fam:

Now removing libfam0 seems like the logical thing to do...
...but a quick look at the dependencies for libfam0, caused me a moment of pause:

And the way to reassure yourself is to preview the changes after choosing (!: Apply):

The output from aptitude includes the phrase 'removing anyway as you requested', which has me wondering?

Now a dpkg summary shows my system having gamin installed rather than fam:
The key to understanding how and why this works is to realise that, in Debian Squeeze, libgamin0 has been marked as a drop in replacement for libfam0 as shown here:

Which means that you can ignore any 'removing anyway as you requested' messages, and know that your system, has not been broken by your actions.
My system has no Nautilus file manager but instead uses Thunar:

...and as thunar recommends gamin, it is a shame that gamin, rather than fam, was not on my system automatically.
Now to see if my file manager is picking up changes to the underlying files in realtime :)